TL;DR:
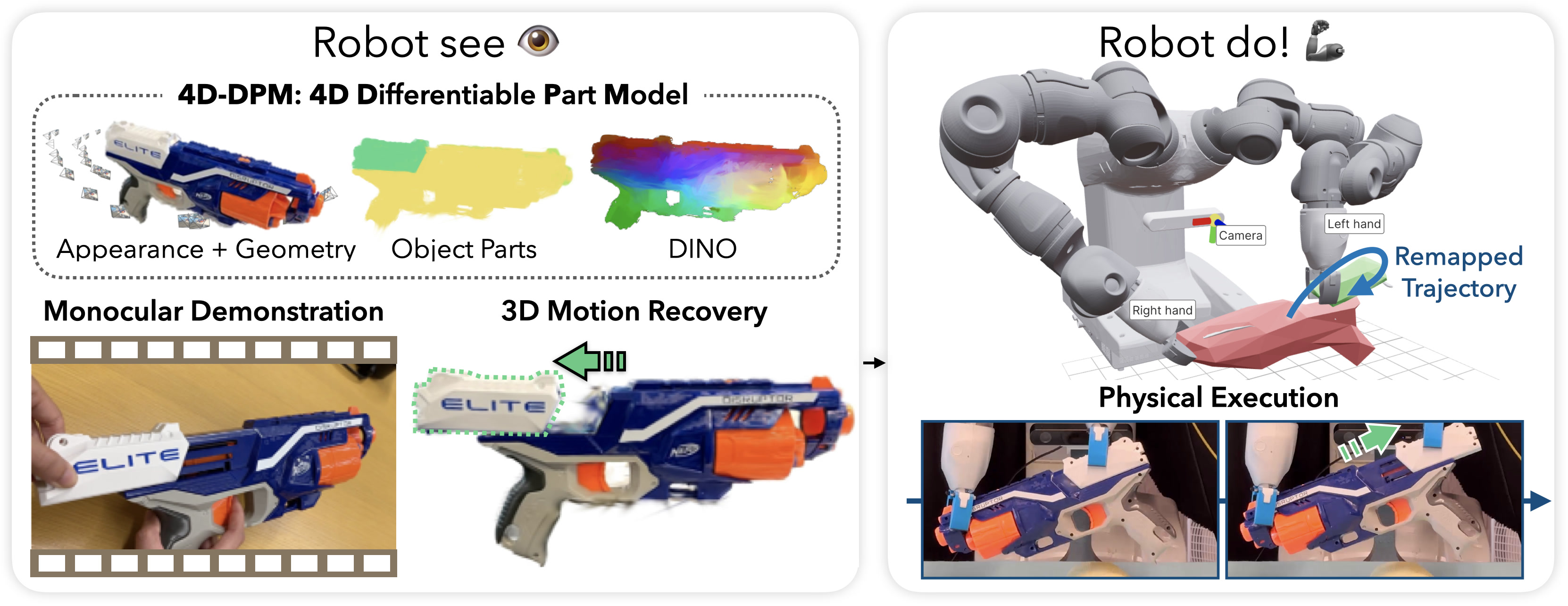
Robot See Robot Do uses a 4DDifferentiable Part Model (4D-DPM) to visually imitate articulated motions from an object scan and single monocular video.
Humans imitate manipulation by watching object motion, not hand motion. RSRD does the same.
This enables imitation from a single video robust to orientation and across the human-robot embodiment gap.
4D Part Reconstruction
RSRD takes in 1) a multi-view object scan and 2) a monocular demonstration video.
By creating part-aware 3D representations using GARField (parts, toggle for clusters) and
DINOv2 (tracking SE3 pose),
these smartphone-captured inputs can generate these 4D reconstructions:
Input demonstration video
Click and move me!
These 4D reconstructions are rendered in-browser! If you think that's cool, check out Viser!
Robot Motion Retargeting
After recovering 3D part motion, RSRD optimizes grasps and robot motions to reproduce the 4D reconstructions.
Click and move me!
These can be physically executed on a real robot to produce the demonstrated motion:
RSRD's visual imitation is object-centric, allowing it to adapt to different object orientations with the same demo:
0 degrees rotated
180 degrees rotated
0 degrees rotated
30 degrees rotated
45 degrees rotated
How it works
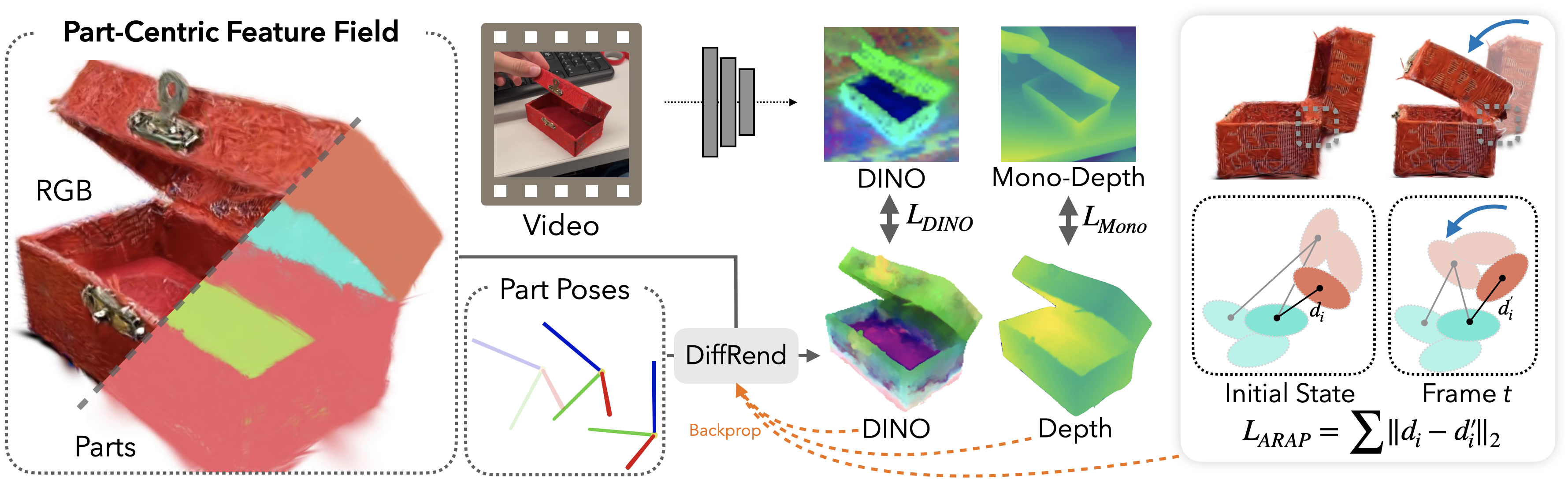
4D Differentiable Part Models
4D-DPM decomposes objects into parts with GARField, and trains part-centric feature fields
on top of these. Each part is assigned a trainable 6D pose parameter which is optimized with gradient descent.
DINO improves dramatically over photometric tracking as a more robust feature target, and allows reconstructing a broad range of open-world objects.
Because 4D-DPM uses gradient descent, any differentiable prior is easily incorporated like temporal smoothness and rigidity.
Retargeting Robot Trajectory
With the recovered 3D part motion and the object placed in the robot workspace,
RSRD now can do the motion demonstrated in the video.
Motions can be retargeted regardless of object pose!
Three main takeaways are:
Hand-Guided Part Selection:
From the 4D motion reconstruction, RSRD must automatically detect which parts need to be manipulated to reproduce it.
Not all moving parts are relevant, like the wooden figurine's hand.
We use hand position as prior for part selection (using HaMeR),
but do not use the hand contact points, as explained in (2).
Part-centric Grasps:
We cannot use detected finger contact locations as grasp points, as they may either jitter or become kinematically unreachable.
Also, a robot must remain rigidly attached to the object part during the entire motion, whileas
humans can do so much more — change contact points by shuffling fingers, or do prehensile motions.
Bimanual Robot Pose Optimization:
We exhaustively search for collision-free, kinematically feasible robot trajectories: we first use
jaxls
to optimize a robot trajectory to fit the robot end-effector waypoints using a Levenberg-Marquardt solver.
Then, we use
cuRobo
to plan collision-free robot approach motions and for all collision avoidance checks.
Below we vary the object pose, and visualize below some bimanual IK solutions for each object motion.
Limitations and Failures
4D monocular reconstruction is an extremely under-constrained and challenging problem, and 4D-DPM still suffers from sensitivity to demonstration viewpoint, occlusions, reconstruction quality, and more.
It also requires some hyper-parameter tuning of regularizers like the ARAP loss, and can frustratingly fail due to incorrect or incomplete part segmentations. More work is needed to adapt the approach for more in-the-wild videos.
In addition, while we show how the 4D reconstruction enables a robot to imitate with motion planning, RSRD as designed cannot scale to multiple demonstration videos of the same object, it can only mimick motion from one video.
Learning to manipulate from more demonstrations, perhaps with policy learning, is an exciting future direction!
Camera Angle Sensitivity: Since RSRD uses only a single video, it can be sensitive to camera pose during the demonstration, as illustrated in the tracking failure below.
The same scan of the laptop can work or fail depending on the camera angle.
Difficulty with feature-less parts: 4D-DPM can struggle with parts which look similar from multiple angles, or have
not enough visual features for DINO to pick up on. In these videos the tail of the plushie and cable of the charger rotate along their major axis, making robot
execution difficult.
Poor segmentation or reconstruction: If the object scan is poor, or the part segmentation is incomplete or severely over-segmented,
4D-DPM can be unstable and lead to catastrophic failure like below.
Hand occlusions: hand occlusions can interfere with part motion recovery, such as with the leg of this sculpture
Citation
If you use this work or find it helpful, please consider citing: (bibtex)
@inproceedings{kerr2024rsrd,
title={Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction},
author={Justin Kerr and Chung Min Kim and Mingxuan Wu and Brent Yi and Qianqian Wang and Ken Goldberg and Angjoo Kanazawa},
booktitle={8th Annual Conference on Robot Learning},
year={2024},
url={https://openreview.net/forum?id=2LLu3gavF1}
}



 Click and move me!
Click and move me!